Hello, all,
With great enthusiasm for the parade of bots we’ve unleashed upon Twitter, I’m writing to introduce you to @OldEnglishBot, my Old English-in-translation utterance generator, and to share the process of its creation.
As you’ve probably gathered from my signature catchphrase, “as a medievalist…” (sorry about that), I have a particular interest in the early stuff: especially Old English verse and prose. This, of course, necessitated learning Old English, which isn’t known as a riotously fun process and also has waning institutional support (not at CUNY Grad Center, though!). This is unfortunate, because there is a rich trove of Old English poetry: much of which has influenced twentieth-century poetics, and also deserves new or experimental translation—check out the Old English Poetry Project for examples of the latter. I’ve been thinking a lot lately about how to make Old English literature accessible and interesting to non-medievalist scholars, so we can buck the stereotype that early medieval study is a dusty old activity that exists in isolation from English literature at large.
Enter @OldEnglishBot, my Twitter experiment. I wanted to produce a bot that could create a conversation about Old English for more than just early medieval scholars. So instead of producing tweets in Old English—which sort of defeats the purpose of Twitter’s skimming format, since you’d have to slow down and translate them, and that would render the bot totally uninteresting to most of the population, academic or otherwise—I decided to make this an experiment in translation, too. My goal was to take a corpus of Old English words in translation, and then generate random utterances from this data set. These utterances, I feel, might offer a creative way of envisioning the type of themes, sentiments, and general moods that Old English can express—serving as a creative deformance, after Jerome McGann and Lisa Samuels in “Deformance and Interpretation,” to perhaps draw scholars, and even poets, into this evocative world of study.
I used a list of words generated by Professor Christine Rauer, of University of Saint Andrews, that she describes as a core vocabulary for Old English. According to her introduction to the list, the words are selected based on their frequency across the Old English corpus, or their “importance on account of their literary or linguistic usage.” The list is available here: http://www.st-andrews.ac.uk/~cr30/vocabulary/. Her list was ideal as a starting point for this bot project, since it contained approximately 500 words, and was also categorized according to part of speech—which came in handy later.
While future iterations of @OldEnglishBot might be best served by a complete Old English corpus, which does not yet exist online, I might see if further research yields a digitized copy of either the Clark-Hall or Bosworth-Toller dictionaries, which could yield a fuller picture of Old English words.
I think the idea of Twitter bots is very pedagogically inspiring, and wanted to experiment with ways to create bots that I could easily teach to others. So, I searched for a protocol that could produce a bot quickly so I could get to the good stuff—looking at tweets, theorizing their results, and thinking critically about play and deformance in algorithmic settings. Professor Zac Whalen, at the University of Mary Washington, has produced an ideal tool for this: a Twitter bot that can be produced in about half an hour, minus data preparation, based on a Google Spreadsheet. You can read more about his painfully simple instructions here: http://www.zachwhalen.net/posts/using-google-spreadsheets-for-a-generated-text-twitter-bot, and about his own thoughts on Twitter bots, poetics, and Markov chains here: http://www.zachwhalen.net/posts/twitter-bots-markov-chains-and-large-slices-of-clarity.
Most of the time spent in this Twitter bot exercise was spent formatting my data. I used an Excel spreadsheet to separate strings into individual columns, which I then sorted by part of speech. For words that had two or more meanings or connotations, I created an additional entry for each meaning so that my columns each had one word, and I regularized the verbs from infinitive form into third person present singular tense in modern English. Since Whalen’s protocol randomly generates utterances, I anticipate the verbs to cause some problems at certain points because not all my nouns are singular, but decided to give it an imperfect shot for my first try. Also, I elected not to use punctuation, since Old English manuscripts do not use it—I thought it might be useful and intriguing to let meanings proliferate by keeping orthography to a minimum.
Ultimately, this database component was a great reminder of how our language learning processes a variety of rather complex compositional rules, and the capabilities or limitations of replicating this process in digital environments—and it would be a great pedagogical activity, too. If I were to teach Twitter bots, especially in an undergraduate course or to scholars that are not computer experts (like me), I would discuss bots and their theoretical interest, assign the conception of a bot and the creation of a corpus database in preparation for the next class, and then use Professor Whalen’s super-simple tool to make the bots in class (it really is that easy). I would have students set them on two or three minute timers so we could discuss our bot creations, troubleshoot, and consider what questions bots raise for humanities study in real time!
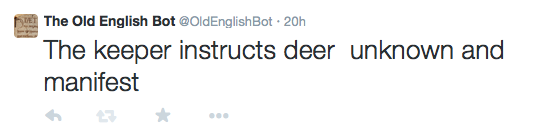
I’m still watching the results unfold, and tweaking with my corpus in order to produce the most consistent results, but I’ve had some great Tweets out of the gate: “The lord produces consolation dear and far,” “The counsellor repents lord cold and eager for praise,” and “The keeper instructs deer unknown and manifest,” all have a definitively Anglo-Saxon feel, and give a good sense of the types of utterances that do in fact occur in Old English. There’s also an interesting poetic vibe to these utterances, and I’d love to get more poets involved to do surrealist poetry exercises with these tweets. One such poet on my list is Conley Lowrance, bot-creator of @poet_noir, who writes poetry based on surrealist techniques and the element of the uncanny and chance in detective fiction. He is also my husband, which is of course another story, and created his bot after I told him about our class this past Monday—vive la revolution! I know other poets across Twitter are interested in digital composition too, and especially given the troubled boundary between “creative” and “critical” modes of writing that we discussed in class, I think poets have much to add to bot theory and its possibilities.
To conclude for now: I suppose the goal of @OldEnglishBot is to lure unsuspecting poets and scholars in with the atmospheric tone of Old English literature and the pleasurable algorithmic serendipity of bots, so that they will immediately sign up for language courses, start doing radical and exciting translations, and foster a creative and pedagogical community for this literature that I so love. Perhaps this is a lofty goal for a little bot, especially one so buggy as mine, but I certainly think it’s a possibility of algorithmic and deformative play. We will see how it goes as the tweets continue.
~Mary Catherine Kinniburgh.